3 Introducing Riemannian Geometry
We have yet to meet the star of the show. There is one object that we can place on a manifold whose importance dwarfs all others, at least when it comes to understanding gravity. This is the metric.
The existence of a metric brings a whole host of new concepts to the table which, collectively, are called Riemannian geometry. In fact, strictly speaking we will need a slightly different kind of metric for our study of gravity, one which, like the Minkowski metric, has some strange minus signs. This is referred to as Lorentzian Geometry and a slightly better name for this section would be “Introducing Riemannian and Lorentzian Geometry”. However, for our immediate purposes the differences are minor. The novelties of Lorentzian geometry will become more pronounced later in the course when we explore some of the physical consequences such as horizons.
3.1 The Metric
In Section 1, we informally introduced the metric as a way to measure distances between points. It does, indeed, provide this service but it is not its initial purpose. Instead, the metric is an inner product on each vector space .
Definition: A metric is a tensor field that is:
-
•
Symmetric: .
-
•
Non-Degenerate: If, for any , for all then .
With a choice of coordinates, we can write the metric as
The object is often written as a line element and this expression is abbreviated as
This is the form that we saw previously in (1.5). The metric components can extracted by evaluating the metric on a pair of basis elements,
The metric is a symmetric matrix. We can always pick a basis of each so that this matrix is diagonal. The non-degeneracy condition above ensures that none of these diagonal elements vanish. Some are positive, some are negative. Sylvester’s law of inertia is a theorem in algebra which states that the number of positive and negative entries is independent of the choice of basis. (This theorem has nothing to do with inertia. But Sylvester thought that if Newton could have a law of inertia, there should be no reason he couldn’t.) The number of negative entries is called the signature of the metric.
3.1.1 Riemannian Manifolds
For most applications of differential geometry, we are interested in manifolds in which all diagonal entries of the metric are positive. A manifold equipped with such a metric is called a Riemannian manifold. The simplest example is Euclidean space which, in Cartesian coordinates, is equipped with the metric
The components of this metric are simply .
A general Riemannian metric gives us a way to measure the length of a vector at each point,
It also allows us to measure the angle between any two vectors and at each point, using
The metric also gives us a way to measure the distance between two points and along a curve in . The curve is parameterised by , with and . The distance is then
where is a vector field that is tangent to the curve. If the curve has coordinates , the tangent vector is , and the distance is
Importantly, this distance does not depend on the choice of parameterisation of the curve; this is essentially the same calculation that we did in Section 1.2 when showing the reparameterisation invariance of the action for a particle.
3.1.2 Lorentzian Manifolds
For the purposes of general relativity, we will be working with a manifold in which one of the diagonal entries of the metric is negative. A manifold equipped with such a metric is called Lorentzian.
The simplest example of a Lorentzian metric is Minkowski space. This is equipped with the metric
The components of the Minkowski metric are . As this example shows, on a Lorentzian manifold we usually take the coordinate index to run from .
At any point on a general Lorentzian manifold, it is always possible to find an orthonormal basis of such that, locally, the metric looks like the Minkowski metric
| (3.93) |
This fact is closely related to the equivalence principle; we’ll describe the coordinates that allow us to do this in Section 3.3.2.
In fact, if we find one set of coordinates in which the metric looks like Minkowski space at , it is simple to exhibit other coordinates. Consider a different basis of vector fields related by
Then, in this basis the components of the metric are
This leaves the metric in Minkowski form at if
| (3.94) |
This is the defining equation for a Lorentz transformation that we saw previously in (1.15). We see that viewed locally – which here means at a point – we recover some basic features of special relativity. Note, however, that if we choose coordinates so that the metric takes the form (3.93) at some point , it will likely differ from the Minkowski metric as we move away from .
The fact that, locally, the metric looks like the Minkowski metric means that we can import some ideas from special relativity. At any point , a vector is said to be timelike if , null if , and spacelike if .
At each point on , we can then draw lightcones, which are the null tangent vectors at that point. There are both past-directed and future-directed lightcones at each point, as shown in Figure 21. The novelty is that the directions of these lightcones can vary smoothly as we move around the manifold. This specifies the causal structure of spacetime, which determines who can be friends with whom. We’ll see more of this later in the lectures.
We can again use the metric to determine the length of curves. The nature of a curve at a point is inherited from the nature of its tangent vector. A curve is called timelike if its tangent vector is everywhere timelike. In this case, we can again use the metric to measure the distance along the curve between two points and . Given a parametrisation , this distance is,
This is called the proper time. It is, in fact, something we’ve met before: it is precisely the action (1.28) for a point particle moving in the spacetime with metric .
3.1.3 The Joys of a Metric
Whether we’re on a Riemannian or Lorentzian manifold, there are a number of bounties that the metric brings.
The Metric as an Isomophism
First, the metric gives us a natural isomorphism between vectors and covectors, for each , with the one-form constructed from the contraction of and a vector field .
In a coordinate basis, we write . This is mapped to a one-form which, because this is a natural isomorphism, we also call . This notation is less annoying than you might think; in components the one-form is written is as . The components are then related by
Physicists usually say that we use the metric to lower the index from to . But in their heart, they mean “the metric provides a natural isomorphism between a vector space and its dual”.
Because is non-degenerate, the matrix is invertible. We denote the inverse as , with . Here can be thought of as the components of a symmetric tensor . More importantly, the inverse metric allows us to raise the index on a one-form to give us back the original tangent vector,
In Euclidean space, with Cartesian coordinates, the metric is simply which is so simple it hides the distinction between vectors and one-forms. This is the reason we didn’t notice the difference between these spaces when we were five.
The Volume Form
The metric also gives us a natural volume form on the manifold . On a Riemannian manifold, this is defined as
The determinant is usually simply written as . On a Lorentzian manifold, the determinant is negative and we instead have
| (3.95) |
As defined, the volume form looks coordinate dependent. Importantly, it is not. To see this, introduce some rival coordinates , with
In the new coordinates, the wedgey part of the volume form becomes
We can rearrange the one-forms into the order . We pay a price of or depending on whether is an even or odd permutation of . Since we’re summing over all indices, this is the same as summing over all permutations of , and we have
where if the change of coordinates preserves the orientation. This factor of is the usual Jacobian factor that one finds when changing the measure in an integral.
Meanwhile, the metric components transform as
and so the determinant becomes
We see that the factors of cancel, and we can equally write the volume form as
The volume form (3.95) may look more familiar if we write it as
Here the components are given in terms of the totally anti-symmetric object with and other components determined by the sign of the permutation,
| (3.96) |
Note that is a tensor, which means that can’t quite be a tensor: instead, it is a tensor divided by . It is sometimes said to be a tensor density. The anti-symmetric tensor density arises in many places in physics. In all cases, it should be viewed as a volume form on the manifold. (In nearly all cases, this volume form arises from a metric as here.)
As with other tensors, we can use the metric to raise the indices and construct the volume form with all indices up
where we get a sign for a Riemannian manifold, and a sign for a Lorentzian manifold. Here is again a totally anti-symmetric tensor density with . Note, however, that while we raise the indices on using the metric, this statement doesn’t quite hold for which takes values 1 or 0 regardless of whether the indices are all down or all up. This reflects the fact that it is a tensor density, rather than a genuine tensor.
The existence of a natural volume form means that, given a metric, we can integrate any function over the manifold. We will sometimes write this as
The metric provides a measure on the manifold that tells us what regions of the manifold are weighted more strongly than the others in the integral.
The Hodge Dual
On an oriented manifold , we can use the totally anti-symmetric tensor to define a map which takes a -form to an -form, denoted , defined by
| (3.97) |
This map is called the Hodge dual. It is independent of the choice of coordinates.
It’s not hard to check that,
| (3.98) |
where the sign holds for Riemannian manifolds and the sign for Lorentzian manifolds. (To prove this, it’s useful to first show that , again with the sign for Riemannian/Lorentzian manifolds.)
It’s worth returning to some high school physics and viewing it through the lens of our new tools. We are very used to taking two vectors in , say and , and taking the cross-product to find a third vector
In fact, we really have objects that live in three different spaces here, related by the Euclidean metric . First we use this metric to relate the vectors to one-forms. The cross-product is then really a wedge product which gives us back a 2-form. We then use the metric twice more, once to turn the two-form back into a one-form using the Hodge dual, and again to turn the one-form into a vector. Of course, none of these subtleties bothered us when we were 15. But when we start thinking about curved manifolds, with a non-trivial metric, these distinctions become important.
The Hodge dual allows us to define an inner product on each . If , we define
which makes sense because and so is a top form that can be integrated over the manifold.
With such an inner product in place, we can also start to play the kind of games that are familiar from quantum mechanics and look at operators on and their adjoints. The one operator that we have introduced on the space of forms is the exterior derivative, defined in Section 2.4.1. Its adjoint is defined by the following result:
Claim: For and ,
| (3.99) |
where the adjoint operator is given by
with, again, the sign for Riemannian/Lorentzian manifolds respectively.
Proof: This is simply the statement of integration-by-parts for forms. On a closed manifold , Stokes’ theorem tells us that
The first term is simply . The second term also takes the form of an inner product which, up to a sign, is proportional to . To determine the sign, note that so, using (3.98), we have . Putting this together gives
as promised.
3.1.4 A Sniff of Hodge Theory
We can combine and to construct the Laplacian, , defined as
where the second equality follows because . The Laplacian can be defined on both Riemannian manifolds, where it is positive definite, and Lorentzian manifolds. Here we restrict our discussion to Riemannian manifolds.
Acting on functions , we have (because is a top form so ). That leaves us with,
This form of the Laplacian, acting on functions, appears fairly often in applications of differential geometry.
There is a particularly nice story involving -forms that obey
Such forms are said to be harmonic. An harmonic form is necessarily closed, meaning , and co-closed, meaning . This follows by writing
and noting that the inner product is positive-definite.
There are some rather pretty facts that relate the existence of harmonic forms to de Rham cohomology. The space of harmonic -forms on a manifold is denoted . First, the Hodge decomposition theorem, which we state without proof: any -form on a compact, Riemannian manifold can be uniquely decomposed as
where and and . This result can then be used to prove:
Hodge’s Theorem: There is an isomorphism
where is the de Rham cohomology group introduced in Section 2.4.3. In particular, the Betti numbers can be computed by counting the number of linearly independent harmonic forms,
Proof: First, let’s show that any harmonic form provides a representative of . As we saw above, any harmonic -form is closed, , so . But the unique nature of the Hodge decomposition tells us that for some .
Next, we need to show that any equivalence class can be represented by a harmonic form. We decompose . By definition means that so we have
where, in the final step, we “integrated by parts” and used the fact that . Because the inner product is positive definite, we must have and, hence, . Any other representative of differs by and so, by the Hodge decomposition, is associated to the same harmonic form .
3.2 Connections and Curvature
We’ve already met one version of differentiation in these lectures. A vector field is, at heart, a differential operator and provides a way to differentiate a function . We write this simply as .
As we saw previously, differentiating higher tensor fields is a little more tricky because it requires us to subtract tensor fields at different points. Yet tensors evaluated at different points live in different vector spaces, and it only makes sense to subtract these objects if we can first find a way to map one vector space into the other. In Section 2.2.4, we used the flow generated by as a way to perform this mapping, resulting in the idea of the Lie derivative .
There is, however, a different way to take derivatives, one which ultimately will prove more useful. The derivative is again associated to a vector field . However, this time we introduce a different object, known as a connection to map the vector spaces at one point to the vector spaces at another. The result is an object, distinct from the Lie derivative, called the covariant derivative.
3.2.1 The Covariant Derivative
A connection is a map . We usually write this as and the object is called the covariant derivative. It satisfies the following properties for all vector fields , and ,
-
•
-
•
for all functions .
-
•
where we define
The covariant derivative endows the manifold with more structure. To elucidate this, we can evaluate the connection in a basis of . We can always express this as
| (3.100) |
with the components of the connection. It is no coincidence that these are denoted by the same greek letter that we used for the Christoffel symbols in Section 1. However, for now, you should not conflate the two; we’ll see the relationship between them in Section 3.2.3.
The name “connection” suggests that , or its components , connect things. Indeed they do. We will show in Section 3.3 that the connection provides a map from the tangent space to the tangent space at any other point . This is what allows the connection to act as a derivative.
We will use the notation
This makes the covariant derivative look similar to a partial derivative. Using the properties of the connection, we can write a general covariant derivative of a vector field as
The fact that we can strip off the overall factor of means that it makes sense to write the components of the covariant derivative as
Or, in components,
| (3.101) |
Note that the covariant derivative coincides with the Lie derivative on functions, . It also coincides with the old-fashioned partial derivative: . However, its action on vector fields differs. In particular, the Lie derivative depends on both and the first derivative of while, as we have seen above, the covariant derivative depends only on . This is the property that allows us to write and think of as an operator in its own right. In contrast, there is no way to write “”. While the Lie derivative has its uses, the ability to define means that this is best viewed as the natural generalisation of the partial derivative to curved space.
Differentiation as Punctuation
In a coordinate basis, in which , the covariant derivative (3.101) becomes
| (3.102) |
We will differentiate often. To save ink, we use the sloppy, and sometimes confusing, notation
This means, in particular, that is the component of , rather than the differentiation of the function .
Covariant differentiation is sometimes denoted using a semi-colon
In this convention, the partial derivative is denoted using a mere comma, . The expression (3.102) then reads
I’m proud to say that we won’t adopt the “semi-colon = differentiation” notation in these lectures. Because it’s stupid.
The Connection is Not a Tensor
The defining the connection are not components of a tensor. We can see this immediately from the definition . This is not linear in the second argument, which is one of the requirements of a tensor.
To illustrate this, we can ask what the connection looks like in a different basis,
| (3.103) |
for some invertible matrix . If and are both coordinate bases, then
We know from (2.78) that the components of a tensor transform as
| (3.104) |
We can now compare this to the transformation of the connection components . In the basis , we have
Substituting in the transformation (3.103), we have
We can write this as
Stripping off the basis vectors , we see that the components of the connection transform as
| (3.105) |
The first term coincides with the transformation of a tensor (3.104). But the second term, which is independent of , but instead depends on , is novel. This is the characteristic transformation property of a connection.
Differentiating Other Tensors
We can use the Leibnizarity of the covariant derivative to extend its action to any tensor field. It’s best to illustrate this with an example.
Consider a one-form . If we differentiate , we will get another one-form which, like any one-form, is defined by its action on vector fields . To construct this, we will insist that the connection obeys the Leibnizarity in the modified sense that
But is simply a function, which means that we can also write this as
Putting these together gives
In coordinates, we have
where, crucially, the terms cancel in going from the first to the second line. This means that the overall result is linear in and we may define without reference to the vector field on which is acts. In components, we have
As for vector fields, we also write this as
This kind of argument can be extended to a general tensor field of rank , where the covariant derivative is defined by,
The pattern is clear: for every upper index we get a term, while for every lower index we get a term.
Now that we can differentiate tensors, we will also need to extend our punctuation notation slightly. If more than two subscripts follow a semi-colon (or, indeed, a comma) then we differentiate respect to both, doing the one on the left first. So, for example, .
3.2.2 Torsion and Curvature
Even though the connection is not a tensor, we can use it to construct two tensors. The first is a rank tensor known as torsion. It is defined to act on and by
The other is a rank tensor , known as curvature. It acts on and by
The curvature tensor is also called the Riemann tensor.
Alternatively, we could think of torsion as a map , defined by
Similarly, the curvature can be viewed as a map from to a differential operator acting on ,
| (3.106) |
Checking Linearity
To demonstrate that and are indeed tensors, we need to show that they are linear in all arguments. Linearity in is straightforward. For the others, there are some small calculations to do. For example, we must show that . To see this, we just run through the definitions of the various objects,
We then use and and . The two terms cancel, leaving us with
Similarly, for the curvature tensor we have
Linearity in follows from linearity in . But we still need to check linearity in ,
Thus, both torsion and curvature define new tensors on our manifold.
Components
We can evaluate these tensors in a coordinate basis , with the dual basis . The components of the torsion are
where we’ve used the fact that, in a coordinate basis, . We learn that, even though is not a tensor, the anti-symmetric part does form a tensor. Clearly the torsion tensor is anti-symmetric in the lower two indices
Connections which are symmetric in the lower indices, so have . Such connections are said to be torsion-free.
The components of the curvature tensor are given by
Note the slightly counterintuitive, but standard ordering of the indices; the indices and that are associated to covariant derivatives and go at the end. We have
| (3.107) | |||||
Clearly the Riemann tensor is anti-symmetric in its last two indices
Equivalently, . There are a number of further identities of the Riemann tensor of this kind. We postpone this discussion to Section 3.4.
The Ricci Identity
There is a closely related calculation in which both the torsion and Riemann tensors appears. We look at the commutator of covariant derivatives acting on vector fields. Written in an orgy of anti-symmetrised notation, this calculation gives
The first term vanishes, while the third and fourth terms cancel against each other. We’re left with
| (3.108) |
where the torsion tensor is and the Riemann tensor appears as
which coincides with (3.107). The expression (3.108) is known as the Ricci identity.
3.2.3 The Levi-Civita Connection
So far, our discussion of the connection has been entirely independent of the metric. However, something nice happens if we have both a connection and a metric. This something nice is called the fundamental theorem of Riemannian geometry. (Happily, it’s also true for Lorentzian geometries.)
Theorem: There exists a unique, torsion free, connection that is compatible with a metric , in the sense that
for all vector fields .
Proof: We start by showing uniqueness. Suppose that such a connection exists. Then, by Leibniz
Since , this becomes
By cyclic permutation of , and , we also have
Since the torsion vanishes, we have
We can use this to write the cyclically permuted equations as
Add the first two of these equations, and subtract the third. We find
| (3.109) | |||||
But with a non-degenerate metric, this specifies the connection uniquely. We’ll give an expression in terms of components in (3.110) below.
It remains to show that the object defined this way does indeed satisfy the properties expected of a connection. The tricky one turns out to be the requirement that . We can see that this is indeed the case as follows:
The other properties of the connection follow similarly.
The connection (3.109), compatible with the metric, is called the Levi-Civita connection. We can compute its components in a coordinate basis . This is particularly simple because , leaving us with
Multiplying by the inverse metric gives
| (3.110) |
The components of the Levi-Civita connection are called the Christoffel symbols. They are the objects (1.32) we met already in Section 1 when discussing geodesics in spacetime. For the rest of these lectures, when discussing a connection we will always mean the Levi-Civita connection.
An Example: Flat Space
In flat space , endowed with either Euclidean or Minkowski metric, we can always pick Cartesian coordinates, in which case the Christoffel symbols vanish. However, in other coordinates this need not be the case. For example, in Section 1.1.1, we computed the flat space Christoffel symbols in polar coordinates (1.11). They don’t vanish. But because the Riemann tensor is a genuine tensor, if it vanishes in one coordinate system then it must vanishes in all of them. Given some horrible coordinate system, with , we can always compute the corresponding Riemann tensor to see if the space is actually flat after all.
Another Example: The Sphere
Consider with radius and the round metric
We can extract the Christoffel symbols from those of flat space in polar coordinates (1.11). The non-zero components are
| (3.111) |
From these, it is straightforward to compute the components of the Riemann tensor. They are most simply expressed as and are given by
| (3.112) |
with the other components vanishing.
3.2.4 The Divergence Theorem
Gauss’ Theorem, also known as the divergence theorem, states that if you integrate a total derivative, you get a boundary term. There is a particular version of this theorem in curved space that we will need for later applications.
As a warm-up, we have the following result:
Lemma: The contraction of the Christoffel symbols can be written as
| (3.113) |
On Lorentzian manifolds, we should replace with .
Proof: From (3.110), we have
However, there’s a useful identity for the log of any diagonalisable matrix: they obey
This is clearly true for a diagonal matrix, since the determinant is the product of eigenvalues while the trace is the sum. But both trace and determinant are invariant under conjugation, so this is also true for diagonalisable matrices. Applying it to our metric formula above, we have
which is the claimed result.
With this in hand, we can now prove the following:
Divergence Theorem: Consider a region of a manifold with boundary . Let be an outward-pointing, unit vector orthogonal to . Then, for any vector field on , we have
where is the pull-back of the metric to , and . On a Lorentzian manifold, a version of this formula holds only if is purely timelike or purely spacelike, which ensures that at any point. Proof: Using the lemma above, the integrand is
The integral is then
which now is an integral of an ordinary partial derivative, so we can apply the usual divergence theorem that we are familiar with. It remains only to evaluate what’s happening at the boundary . For this, it is useful to pick coordinates so that the boundary is a surface of constant . Furthermore, we will restrict to metrics of the form
Then by our usual rules of integration, we have
The unit normal vector is given by , which satisfies as it should. We then have , so we can write
which is the result we need. As the final expression is a covariant quantity, it is true in general.
In Section 2.4.5, we advertised Stokes’ theorem as the mother of all integral theorems. It’s perhaps not surprising to hear that the divergence theorem is a special case of Stokes’ theorem. To see this, here’s an alternative proof that uses the language of forms.
Another Proof: Given the volume form on , and a vector field , we can contract the two to define an form . (This is the interior product that we previously met in (2.85).) It has components
If we now take the exterior derivative, , we have a top-form. Since the top form is unique up to multiplication, must be proportional to the volume form. Indeed, it’s not hard to show that
This means that, in form language, the integral over that we wish to consider can be written as
Now we invoke Stokes’ theorem, to write
We now need to massage into the form needed. First, we introduce a volume form on , with components
This is related to the volume form on by
where is the orthonormal vector that we introduced previously. We then have
The divergence theorem then follows from Stokes’ theorem.
3.2.5 The Maxwell Action
Let’s briefly turn to some physics. We take the manifold to be spacetime. In classical field theory, the dynamical degrees of freedom are objects that take values at each point in . We call these objects fields. The simplest such object is just a function which, in physics, we call a scalar field.
As we described in Section 2.4.2, the theory of electromagnetism is described by a one-form field . In fact, there is a little more structure because we ask that the theory is invariant under gauge transformations
To achieve this, we construct a field strength which is indeed invariant under gauge transformations. The next question to ask is: what are the dynamics of these fields?
The most elegant and powerful way to describe the dynamics of classical fields is provided by the action principle. The action is a functional of the fields, constructed by integrating over the manifold. The differential geometric language that we’ve developed in these lectures tells us that there are, in fact, very few actions one can write down.
To see this, suppose that our manifold has only the 2-form but is not equipped with a metric. If spacetime has dimension (it does!) then we need to construct a 4-form to integrate over . There is only one of these at our disposal, suggesting the action
If we expand this out in the electric and magnetic fields using (2.87), we find
Actions of this kind, which are independent of the metric, are called topological. They are typically unimportant in classical physics. Indeed, we can locally write , so the action is a total derivative and does not affect the classical equations of motion. Nonetheless, topological actions often play subtle and interesting roles in quantum physics. For example, the action underlies the theory of topological insulators. You can read more about this in Section 1 of the lectures on Gauge Theory.
To construct an action that gives rise to interesting classical dynamics, we need to introduce a metric. The existence of a metric allows us to introduce a second two-form, , and construct the action
This is the Maxwell action, now generalised to a curved spacetime. If we restrict to flat Minkowski space, the components are . As we saw in our lectures on Electromagnetism, varying this action gives the remaining two Maxwell equations. In the elegant language of differential geometry, these take the simple form
We can also couple the gauge field to an electric current. This is described by a one-form , and we write the action
We require that this action is invariant under gauge transformations . The action transforms as
After an integration by parts, the second term vanishes provided that
which is the requirement of current conservation expressed in the language of forms. The Maxwell equations now have a source term, and read
| (3.114) |
We see that the rigid structure of differential geometry leads us by the hand to the theories that govern our world. We’ll see this again in Section 4 when we discuss gravity.
Electric and Magnetic Charges
To define electric and magnetic charges, we integrate over submanifolds. For example, consider a three-dimensional spatial submanifold . The electric charge in is defined to be
It’s simple to check that this agrees with our usual definition in flat Minkowski space. Using the equation of motion (3.114), we can translate this into an integral of the field strength
| (3.115) |
where we have used Stokes’ theorem to write this as an integral over the boundary . The result is the general form of Gauss’ law, relating the electric charge in a region to the electric field piercing the boundary of the region. Similarly, we can define the magnetic charge
When we first meet Maxwell theory, we learn that magnetic charges do not exist, courtesy of the identity . However, this can be evaded in topologically more interesting spaces. We’ll see a simple example in Section 6.2.1 when we discuss charged black holes.
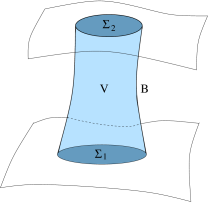
The statement of current conservation means that the electric charge in a region cannot change unless current flows in or out of that region. This fact, familiar from Electromagnetism, also has a nice expression in terms of forms. Consider a cylindrical region of spacetime , ending on two spatial hypersurfaces and as shown in the figure. The boundary of is then
where is the cylindrical timelike hypersurface.
We require that on , which is the statement that no current flows in or out of the region. Then we have
which tells us that the electric charge remains constant in time.
Maxwell Equations Using Connections
The form of the Maxwell equations given above makes no reference to a connection. It does, however, use the metric, buried in the definition of the Hodge .
There is an equivalent formulation of the Maxwell equation using the covariant derivative. This will also serve to highlight the relationship between the covariant and exterior derivatives. First note that, given a one-form , we can define the field strength as
where the Christoffel symbols have cancelled out by virtue of the anti-symmetry. This is what allowed us to define the exterior derivative without the need for a connection.
Next, consider the current one-form . We can recast the statement of current conservation as follows:
As an aside, in Riemannian signature the formula
provides a quick way of computing the divergence in different coordinate systems (if you don’t have the inside cover of Jackson to hand). For example, in spherical polar coordinates on , we have . Plug this into the expression above to immediately find
The Maxwell equation (3.114) can also be written in terms of the covariant derivative
Claim:
| (3.116) |
Proof: We have
where, in the second equality, we’ve again used (3.113) and in the final equality we’ve used the fact that is symmetric while is anti-symmetric. To complete the proof, you need to chase down the definitions of the Hodge dual (3.97) and the exterior derivative (2.81). (If you’re struggling to match factors of , then remember that the volume form is a tensor, while the epsilon symbol is a tensor density.)
3.3 Parallel Transport
Although we have now met a number of properties of the connection, we have not yet explained its name. What does it connect?
The answer is that the connection connects tangent spaces, or more generally any tensor vector space, at different points of the manifold. This map is called parallel transport. As we stressed earlier, such a map is necessary to define differentiation.
Take a vector field and consider some associated integral curve , with coordinates , such that
| (3.117) |
We say that a tensor field is parallely transported along if
| (3.118) |
Suppose that the curve connects two points, and . The requirement (3.118) provides a map from the vector space defined at to the vector space defined at .
To illustrate this, consider the parallel transport of a second vector field . In components, the condition (3.118) reads
If we now evaluate this on the curve , we can think of , which obeys
| (3.119) |
These are a set of coupled, ordinary differential equations. Given an initial condition at, say , corresponding to point , these equations can be solved to find a unique vector at each point along the curve.
Parallel transport is path dependent. It depends on both the connection, and the underlying path which, in this case, is characterised by the vector field .
This is the second time we’ve used a vector field to construct maps between tensors at different points in the manifold. In Section 2.2.2, we used to generate a flow , which we could then use to pull-back or push-forward tensors from one point to another. This was the basis of the Lie derivative. This is not the same as the present map. Here, we’re using only to define the curve, while the connection does the work of relating vector spaces along the curve.
3.3.1 Geodesics Revisited
A geodesic is a curve tangent to a vector field that obeys
| (3.120) |
Along the curve , we can substitute the expression (3.117) into (3.119) to find
| (3.121) |
This is precisely the geodesic equation (1.31) that we derived in Section 1 by considering the action for a particle moving in spacetime. In fact, we find that the condition (3.120) results in geodesics with affine parameterisation.
For the Levi-Civita connection, we have . This ensures that for any vector field parallely transported along a geodesic , so , we have
This tells us that the vector field makes the same angle with the tangent vector along each point of the geodesic.
3.3.2 Normal Coordinates
Geodesics lend themselves to the construction of a particularly useful coordinate system. On a Riemannian manifold, in the neighbourhood of a point , we can always find coordinates such that
| (3.122) |
The same holds for Lorentzian manifolds, now with . These are referred to as normal coordinates. Because the first derivative of the metric vanishes, normal coordinates have the property that, at the point , the Christoffel symbols vanish: . Generally, away from we will have . Note, however, that it is not generally possible to ensure that the second derivatives of the metric also vanish. This, in turn, means that it’s not possible to pick coordinates such that the Riemann tensor vanishes at a given point.
There are a number of ways to demonstrate the existence of coordinates (3.122). The brute force way is to start with some metric in coordinates and try to find a change of coordinates to which does the trick. In the new coordinates,
| (3.123) |
We’ll take the point to be the origin in both sets of coordinates. Then we can Taylor expand
We insert this into (3.123), together with a Taylor expansion of , and try to solve the resulting partial differential equations to find the coefficients and that do the job. For example, the first requirement is
Given any , it’s always possible to find so that this is satisfied. In fact, a little counting shows that there are many such choices. If , then there are independent coefficients in the matrix . The equation above puts conditions on these. That still leaves parameters unaccounted for. But this is to be expected: this is precisely the dimension of the rotational group (or the Lorentz group ) that leaves the flat metric unchanged.
We can do a similar counting at the next order. There are independent elements in the coefficients . This is exactly the same number of conditions in the requirement .
We can also see why we shouldn’t expect to set the second derivative of the metric to zero. Requiring is constraints. Meanwhile, the next term in the Taylor expansion is which has independent coefficients. We see that the numbers no longer match. This time we fall short, leaving
unaccounted for. This, therefore, is the number of ways to characterise the second derivative of the metric in a manner that cannot be undone by coordinate transformations. Indeed, it is not hard to show that this is precisely the number of independent coefficients in the Riemann tensor. (For , there are 20 coefficients of the Riemann tensor.)
The Exponential Map
There is a rather pretty, direct way to construct the coordinates (3.122). This uses geodesics. The rough idea is that, given a tangent vector , there is a unique affinely parameterised geodesic through with tangent vector at . We then label any point in the neighbourhood of by the coordinates of the geodesic that take us to in some fixed amount of time. It’s like throwing a ball in all possible directions, and labelling points by the initial velocity needed for the ball to reach that point in, say, 1 second.
Let’s put some flesh on this. We introduce any coordinate system (not necessarily normal coordinates) in the neighbourhood of . Then the geodesic we want solves the equation (3.121) subject to the requirements
There is a unique solution.
This observation means that we can define a map,
Given , construct the appropriate geodesic and the follow it for some affine distance which we take to be . This gives a point . This is known as the exponential map and is illustrated in the Figure 23.
There is no reason that the exponential map covers all of the manifold . It could well be that there are points which cannot be reached from by geodesics. Moreover, it may be that there are tangent vectors for which the exponential map is ill-defined. In general relativity, this occurs if the spacetime has singularities. Neither of these issues are relevant for our current purpose.
Now pick a basis of . The exponential map means that tangent vector defines a point in the neighbourhood of . We simply assign this point coordinates
These are the normal coordinates.
If we pick the initial basis to be orthonormal, then the geodesics will point in orthogonal directions which ensures that the metric takes the form .
To see that the first derivative of the metric also vanishes, we first fix a point associated to a given tangent vector . This tells us that the point sits a distance along the geodesic. We can now ask: what tangent vector will take us a different distance along this same geodesic? Because the geodesic equation (3.121) is homogeneous in , if we halve the length of then we will travel only half the distance along the geodesic, i.e. to . In general, the tangent vector will take us a distance along the geodesic
This means that the geodesics in these coordinates take the particularly simply form
Since these are geodesics, they must solve the geodesic equation (3.121). But, for trajectories that vary linearly in time, this is just
This holds at any point along the geodesic. At most points , this equation only holds for those choices of which take us along the geodesic in the first place. However, at , corresponding to the point of interest, this equation must hold for any tangent vector . This means that which, for a torsion free connection, ensures that .
Vanishing Christoffel symbols means that the derivative of the metric vanishes. This follows for the Levi-Civita connection by writing . Symmetrising over means that the last two terms cancel, leaving us with when evaluated at .
The Equivalence Principle
Normal coordinates play an important conceptual role in general relativity. Any observer at point who parameterises her immediate surroundings using coordinates constructed by geodesics will experience a locally flat metric, in the sense of (3.122).
This is the mathematics underlying the Einstein equivalence principle. This principle states that any freely falling observer, performing local experiments, will not experience a gravitational field. Here “freely falling” means the observer follows geodesics, as we saw in Section 1 and will naturally use normal coordinates. In this context, the coordinates are called a local inertial frame. The lack of gravitational field is the statement that .
Key to understanding the meaning and limitations of the equivalence principle is the word “local”. There is a way to distinguish whether there is a gravitational field at : we compute the Riemann tensor. This depends on the second derivative of the metric and, in general, will be non-vanishing. However, to measure the effects of the Riemann tensor, one typically has to compare the result of an experiment at with an experiment at a nearby point : this is considered a “non-local” observation as far as the equivalence principle goes. In the next two subsections, we give examples of physics that depends on the Riemann tensor.
3.3.3 Path Dependence: Curvature and Torsion
Take a tangent vector , and parallel transport it along a curve to some point . Now parallel transport it along a different curve to the same point . How do the resulting vectors differ?
To answer this, we construct each of our curves and from two segments, generated by linearly independent vector fields, and satisfying as shown in Figure 24. To make life easy, we’ll take the point to be close to the original point .
We pick normal coordinates so that the starting point is at while the tangent vectors are aligned along the coordinates, and . The other corner points are then , and where and are taken to be small. This set-up is shown in Figure 24.
First we parallel transport along to . Along the curve, solves (3.119)
| (3.124) |
We Taylor expand the solution as
From (3.124), we have because, in normal coordinates, . We can calculate the second derivative by differentiating (3.124) to find
Here the second line follows because we’re working in normal coordinates at , and the final line because is the parameter along the integral curve of , so . We therefore have
| (3.126) |
Now we parallel transport once more, this time along to . The Taylor expansion now takes the form
| (3.127) |
We can again evaluate the first derivative using the analog of the parallel transport equation (3.124),
Since we’re working in normal coordinates about and not , we no longer get to argue that this term vanishes. Instead we Taylor expand about to get
Note that in principle we should also Taylor expand and but, at leading order, these will multiply , so they only contribute at next order. The second order term in the Taylor expansion (3.127) involves and there is an expression similar to (3.3.3). To leading order the and terms are again absent because they are multiplied by . We therefore have
where we replaced the point with point because they differ only subleading terms proportional to . The upshot is that this time the difference between and involves two terms,
Finally, we can relate to using the expression (3.126) that we derived previously. We end up with
where denotes any terms cubic or higher in small quantities.
Now suppose we go along the path , first visiting point and then making our way to . We can read the answer off directly from the result above, simply by swapping and and and ; only the middle term changes,
We find that
where, in the final equality, we’ve used the expression for the Riemann tensor in components (3.107), which simplifies in normal coordinates as . Note that, to the order we’re working, we could equally as well evaluate at the point ; the two differ only by higher order terms.
Although our calculation was performed with a particular choice of coordinates, the end result is written as an equality between tensors and must, therefore, hold in any coordinate system. This is a trick that we will use frequently throughout these lectures: calculations are considerably easier in normal coordinates. But if the resulting expression relate tensors then the final result must be true in any coordinate system.
We have discovered a rather nice interpretation of the Riemann tensor: it tells us the path dependence of parallel transport. The calculation above is closely related to the idea of holonomy. Here, one transports a vector around a closed curve and asks how the resulting vector compares to the original. This too is captured by the Riemann tensor. A particularly simple example of non-trivial holonomy comes from parallel transport of a vector on a sphere: the direction that you end up pointing in depends on the path you take.
The Meaning of Torsion
We discarded torsion almost as soon as we met it, choosing to work with the Levi-Civita connection which has vanishing torsion, . Moreover, as we will see in Section 4, torsion plays no role in the theory of general relativity which makes use of the Levi-Civita connection. Nonetheless, it is natural to ask: what is the geometric meaning of torsion? There is an answer to this that makes use of the kind of parallel transport arguments we used above.
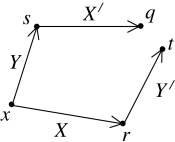
This time, we start with two vectors . We pick coordinates and write these vectors as and . Starting from , we can use these two vectors to construct two points infinitesimally close to . We call these points and respectively: they have coordinates
where is some infinitesimal parameter.
We now parallel transport the vector along the direction of to give a new vector . Similarly, we parallel transport along the direction of to get a new vector . These new vectors have components
Each of these tangent vectors now defines a new point. Starting from point , and moving in the direction of , we see that we get a new point with coordinates
Meanwhile, if we sit at point and move in the direction of , we get to a typically different point, , with coordinates
We see that if the connection has torsion, so , then the two points and do not coincide. In other words, torsion measures the failure of the parallelogram shown in figure to close.
3.3.4 Geodesic Deviation
Consider now a one-parameter family of geodesics, with coordinates . Here is the affine parameter along the geodesics, all of which are tangent to the vector field so that, along the surface spanned by , we have
Meanwhile, labels the different geodesics, as shown in Figure 26. We take the tangent vector in the direction to be generated by a second vector field so that,
The tangent vector is sometimes called the deviation vector; it takes us from one geodesic to a nearby geodesic with the same affine parameter .
The family of geodesics sweeps out a surface embedded in the manifold. This gives us some freedom in the way we assign coordinates and . In fact, we can always pick coordinates and on the surface such that and , ensuring that
Roughly speaking, we can do this if we use and as coordinates on some submanifold of . Then the vector fields can be written simply as and and .
We can ask how neighbouring geodesics behave. Do they converge? Or do they move further apart? Now consider a connection with vanishing torsion, so that . Since , we have
where, in the second equality, we’ve used the expression (3.106) for the Riemann tensor as a differential operator. But because is tangent to geodesics, and we have
In index notation, this is
If we further restrict to an integral curve associated to the vector field , as in (3.117), this equation is sometimes written as
| (3.128) |
where is the covariant derivative along the curve , defined by . The left-hand-side tells us how the deviation vector changes as we move along the geodesic. In other words, it is the relative acceleration of neighbouring geodesics. We learn that this relative acceleration is controlled by the Riemann tensor.
Experimentally, such geodesic deviations are called tidal forces. We met a simple example in Section 1.2.4.
An Example: the Sphere Again
It is simple to determine the geodesics on the sphere of radius . Using the Christoffel symbols (3.111), the geodesic equations are
The solutions are great circles. The general solution is a little awkward in these coordinates, but there are two simple solutions.
-
•
We can set with and . This is a solution in which the particle moves around the equator. Note that this solution doesn’t work for other values of .
-
•
We can set and . These are paths of constant longitude and are geodesics for any constant value of . Note, however, that our coordinates go a little screwy at the poles and .
To illustrate geodesic deviation, we’ll look at the second class of solutions; the particle moves along , with the angle specifying the geodesic. This set-up is simple enough that we don’t need to use any fancy Riemann tensor techniques: we can just understand the geodesic deviation using simple geometry. The distance between the geodesic at and the geodesic at some other longitude is
| (3.129) |
Now let’s re-derive this result using our fancy technology. The geodesics are generated by the vector field . Meanwhile, the separation between geodesics at a fixed is . The geodesic deviation equation in the form (3.128) is
We computed the Riemann tensor for in (3.112); the relevant component is
| (3.130) |
and the geodesic deviation equation becomes simply
which is indeed solved by (3.129).
3.4 More on the Riemann Tensor and its Friends
Recall that the components of the Riemann tensor are given by (3.107),
| (3.131) |
We can immediately see that the Riemann tensor is anti-symmetric in the final two indices
However, there are also a number of more subtle symmetric properties satisfied by the Riemann tensor when we use the Levi-Civita connection. Logically, we could have discussed this back in Section 3.2. However, it turns out that a number of statements are substantially simpler to prove using normal coordinates introduced in Section 3.3.2.
Claim: If we lower an index on the Riemann tensor, and write then the resulting object also obeys the following identities
-
•
.
-
•
.
-
•
.
-
•
.
Proof: We work in normal coordinates, with at a point. The Riemann tensor can then be written as
where, in going to the second line, we used the fact that in normal coordinates. The first three symmetries are manifest; the final one follows from a little playing. (It is perhaps quicker to see the final symmetry if we return to the Christoffel symbols where, in normal coordinates, we have .) But since the symmetry equations are tensor equations, they must hold in all coordinate systems.
Claim: The Riemann tensor also obeys the Bianchi identity
| (3.132) |
Alternatively, we can anti-symmetrise on the final two indices, in which case this can be written as .
Proof: We again use normal coordinates, where at the point . Schematically, we have , so and the final term is absent in normal coordinates. This means that we just have which, in its full coordinated glory, is
Now anti-symmetrise on the three appropriate indices to get the result.
For completeness, we should mention that the identities and (sometimes called the first and second Bianchi identities respectively) are more general, in the sense that they hold for an arbitrary torsion free connection. In contrast, the other two identities, and hold only for the Levi-Civita connection.
3.4.1 The Ricci and Einstein Tensors
There are a number of further tensors that we can build from the Riemann tensor.
First, given a rank tensor, we can always construct a rank tensor by contraction. If we start with the Riemann tensor, the resulting object is called the Ricci tensor. It is defined by
The Ricci tensor inherits its symmetry from the Riemann tensor. We write , giving us
We can go one step further and create a function over the manifold. This is the Ricci scalar,
The Bianchi identity (3.132) has a nice implication for the Ricci tensor. If we write the Bianchi identity out in full, we have
which means that
This motivates us to introduce the Einstein tensor,
which has the property that it is covariantly constant, meaning
| (3.133) |
We’ll be seeing much more of the Ricci and Einstein tensors in the next section.
3.4.2 Connection 1-forms and Curvature 2-forms
Calculating the components of the Riemann tensor is straightforward but extremely tedious. It turns out that there is a slightly different way of repackaging the connection and the torsion and curvature tensors using the language of forms. This not only provides a simple way to actually compute the Riemann tensor, but also offers some useful conceptual insight.
Vielbeins
Until now, we have typically worked with a coordinate basis . However, we could always pick a basis of vector fields that has no such interpretation. For example, a linear combination of a coordinate basis, say
will not, in general, be a coordinate basis itself.
Given a metric, there is a non-coordinate basis that will prove particularly useful for computing the curvature tensor. This is the basis such that, on a Riemannian manifold,
Alternatively, on a Lorentzian manifold we take
| (3.134) |
The components are called vielbeins or tetrads. (On an -dimensional manifold, these objects are usually called “German word for ”-beins. For example, one-dimensional manifolds have einbeins; four-dimensional manifolds have vierbeins.)
The is reminiscent of our discussion in Section 3.1.2 where we mentioned that we can always find coordinates so that any metric will look flat at a point. In (3.134), we’ve succeeded in making the manifold look flat everywhere (at least in a patch covered by a chart). There are no coordinates that do this, but there’s nothing to stop us picking a basis of vector fields that does the job. In what follows, indices are raised/lowered with the metric while indices are raised/lowered with the flat metric or . We will phrase our discussion in the context of Lorentzian manifolds, with an eye to later applications to general relativity.
The vielbeins aren’t unique. Given a set of vielbeins, we can always find another set related by
| (3.135) |
These are Lorentz transformations. However now they are local Lorentz transformation, because can vary over the manifold. These local Lorentz transformations are a redundancy in the definition of the vielbeins in (3.134).
The dual basis of one-forms is defined by . They are related to the coordinate basis by
Note the different placement of indices: is the inverse of , meaning it satisfies and . In the non-coordinate basis, the metric on a Lorentzian manifold takes the form
For Riemannian manifolds, we replace with .
The Connection One-Form
Given a non-coordinate basis , we can define the components of a connection in the usual way (3.100)
Note that, annoyingly, these are not the same functions as , which are the components of the connection computed in the coordinate basis! You need to pay attention to whether the components are Greek etc which tells you that we’re in the coordinate basis, or Roman etc which tells you we’re in the vielbein basis.
We then define the matrix-valued connection one-form as
| (3.136) |
This is sometimes referred to as the spin connection because of the role it plays in defining spinors on curved spacetime. We’ll describe this in Section 4.5.6.
The connection one-forms don’t transform covariantly under local Lorentz transformations (3.135). Instead, in the new basis, the components of the connection one-form are defined as . You can check that the connection one-form transforms as
| (3.137) |
The second term reflects the fact that the original connection components do not transform as a tensor, but with an extra term involving the derivative of the coordinate transformation (3.105). This now shows up as an extra term involving the derivative of the local Lorentz transformation.
There is a rather simple way to compute the connection one-forms, at least for a torsion free connection. This follows from the first of two Cartan structure relations:
Claim: For a torsion free connection,
| (3.138) |
Proof: We first look at the second term,
The components are related to the coordinate basis components by
| (3.139) |
So
where, in the second line we’ve used and the fact that the connection is torsion free so . Now we use the fact that , so . We have
which completes the proof.
The discussion above was for a general connection. For the Levi-Civita connection, we have a stronger result
Claim: For the Levi-Civita connection, the connection one-form is anti-symmetric
| (3.140) |
Proof: This follows from the explicit expression (3.139) for the components . Lowering an index, we have
where, in the final equality, we’ve used the fact that the connection is compatible with the metric to raise the indices of inside the covariant derivative. Finishing off the derivation, we then have
The result then follows from the definition .
The Cartan structure equation (3.138), together with the anti-symmetry condition (3.140), gives a quick way to compute the spin connection. It’s instructive to do some counting to see how these two equations uniquely define . In particular, since is anti-symmetric, one might think that it has independent components, and these can’t possibly be fixed by the Cartan structure equations (3.138). But this is missing the fact that are not numbers, but are one-forms. So the true number of components in is . Furthermore, the Cartan structure equation is an equation relating 2-forms, each of which has components. This means that it’s really equations. We see that the counting does work, and the two fix the spin connection uniquely.
The Curvature Two-Form
We can compute the components of the Riemann tensor in our non-coordinate basis,
The anti-symmetry of the last two indices, , makes this ripe for turning into a matrix of two-forms,
| (3.141) |
The second of the two Cartan structure relations states that this can be written in terms of the curvature one-form as
| (3.142) |
The proof of this is mechanical and somewhat tedious. It’s helpful to define the quantities along the way, since they appear on both left and right-hand sides.
3.4.3 An Example: the Schwarzschild Metric
The connection one-form and curvature two-form provide a slick way to compute the curvature tensor associated to a metric. The reason for this is that computing exterior derivatives takes significantly less effort than computing covariant derivatives. We will illustrate this for metrics of the form,
| (3.143) |
For later applications, it will prove useful to compute the Riemann tensor for this metric with general . However, if we want to restrict to the Schwarzschild metric we can take
| (3.144) |
The basis of non-coordinate one-forms is
| (3.145) |
Note that the one-forms should not be confused with the angular coordinate ! In this basis, the metric takes the simple form
We now compute . Calculationally, this is straightforward. In particular, it’s substantially easier than computing the covariant derivative because there’s no messy connection to worry about. The exterior derivatives are simply
The first Cartan structure relation, , can then be used to read off the connection one-form. The first equation tells us that . We then use the anti-symmetry (3.140), together with raising and lowering by the Minkowski metric to get . The Cartan structure equation then gives and the contribution happily vanishes because it is proportional to .
Next, we take to solve the structure equation. The anti-symmetry (3.140) gives and this again gives a vanishing contribution to the structure equation.
Finally, the equation suggests that we take and . These anti-symmetric partners and do nothing to spoil the and structure equations, so we’re home dry. The final result is
Now we can use this to compute the curvature two-form. We will focus on
We have
The second term in the curvature 2-form is . So we’re left with
The other curvature 2-forms can be computed in a similar fashion. We can now read off the components of the Riemann tensor in the non-coordinate basis using (3.141). (We should remember that we get a contribution from both and , which cancels the factor of in (3.141).) After lowering an index, we find that the non-vanishing components of the Riemann tensor are
We can also convert this back to the coordinates using
This is particularly easy in this case because the matrices defining the one-forms (3.145) are diagonal. We then have
| (3.146) | |||||
Finally, if we want to specialise to the Schwarzschild metric with given by (3.144), we have
Although the calculation is a little lengthy, it turns out to be considerably quicker than first computing the Levi-Civita connection and subsequently motoring through to get the Riemann tensor components.
3.4.4 The Relation to Yang-Mills Theory
It is no secret that the force of gravity is geometrical. However, the other forces are equally as geometrical. The underlying geometry is something called a fibre bundle, rather than the geometry of spacetime.
We won’t describe fibre bundles in this course, but we can exhibit a clear similarity between the structures that arise in general relativity and the structures that arise in the other forces, which are described by Maxwell theory and its generalisation to Yang-Mills theory.
Yang-Mills theory is based on a Lie group which, for this discussion, we will take to be or . If we take , then Yang-Mills theory reduces to Maxwell theory. The theory is described in terms of an object that physicists call a gauge potential. This is a spacetime “vector” which lives in the Lie algebra of . In more down to earth terms, each component is an anti-Hermitian matrix, , with . In fact, as we saw above, this “vector” is really a one-form. The novelty is that it’s a Lie algebra-valued one-form.
Mathematicians don’t refer to as a gauge potential. Instead, they call it a connection (on a fibre bundle). This relationship becomes clearer if we look at how changes under a gauge transformation
where . This is identical to the transformation property (3.137) of the one-form connection under local Lorentz transformations.
In Yang-Mills, as in Maxwell theory, we construct a field strength. In components, this is given by
Alternatively, in the language of forms, the field strength becomes
Again, there is an obvious similarity with the curvature 2-form introduced in (3.142). Mathematicians refer to the Yang-Mills field strength the “curvature”.
A particularly quick way to construct the Yang-Mills field strength is to take the commutator of two covariant derivatives. It is simple to check that
where I’ve suppressed the indices on both sides. This is the gauge theory version of the Ricci identity (3.108): for a torsion free connection,