Reseacher: Angelica Aviles-Rivero, and Carola-Bibiane Schönlieb
In this era of big data, deep learning (DL) has reported astonishing results for different tasks in computer vision including image classification, detection and segmentation just to name few. In particular, for the task of image classification, a major breakthrough has been reported in the setting of supervised learning. In this context, majority of methods are based on deep convolutional neural networks including ResNet, VGG and SE-Net in which pre-trained, fine tuned and trained from scratch solutions have been considered. A key factor, for these impressive results, is the assumption of a large corpus of labelled data. These labels can be generated either by humans or automatically on proxy tasks. However, to obtain well-annotated labels is expensive and time consuming, and one should account for either human bias and uncertainty that adversely affect the classification output. These drawbacks have motivated semi-supervised learning (SSL) to be a focus of great interest in the community.
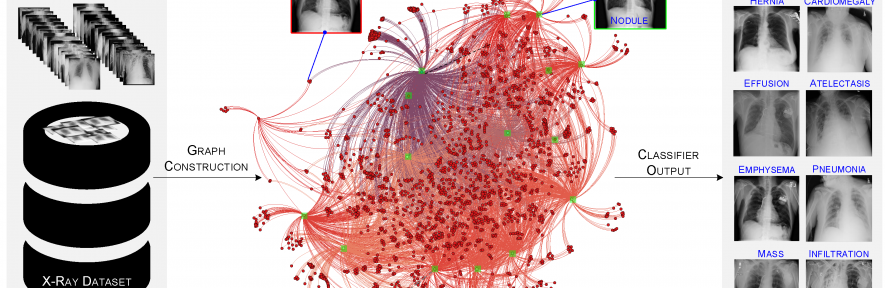
We explore this perspective for large-scale problems such X-ray classification, Hyperspectral data and natural Images.